![]()
Verified DP-100 dumps Q&As - Pass Guarantee Exam Dumps Test Engine [2026]
DP-100 dumps and 519 unique questions
The DP-100 exam covers a wide range of topics, including data exploration, data preparation, modeling, and deployment. You will need to understand key Azure technologies such as Azure Machine Learning, Azure Databricks, and Azure Cosmos DB, as well as programming languages like Python and R. You will also need to be familiar with data storage and processing, data visualization, and machine learning techniques.
The DP-100 certification exam is intended for data scientists, data architects, and data engineers who want to validate their expertise in designing and implementing data science solutions on Azure. It is also suitable for professionals who are responsible for implementing Azure-based machine learning and AI solutions, including data analysts, developers, and IT administrators.
NEW QUESTION # 61
Hotspot Question
You have an Azure Machine Learning workspace named workspace1 that is accessible from a public endpoint. The workspace contains an Azure Blob storage datastore named store1 that represents a blob container in an Azure storage account named account1. You configure workspace1 and account1 to be accessible by using private endpoints in the same virtual network.
You must be able to access the contents of store1 by using the Azure Machine Learning SDK for Python. You must be able to preview the contents of store1 by using Azure Machine Learning studio.
You need to configure store1.
What should you do? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation:
Box 1: Regenerate the keys of account1.
Azure Blob Storage support authentication through Account key or SAS token.
To authenticate your access to the underlying storage service, you can provide either your account key, shared access signatures (SAS) tokens, or service principal Box 2: Update the authentication for store1.
For Azure Machine Learning studio users, several features rely on the ability to read data from a dataset; such as dataset previews, profiles and automated machine learning. For these features to work with storage behind virtual networks, use a workspace managed identity in the studio to allow Azure Machine Learning to access the storage account from outside the virtual network.
Note: Some of the studio's features are disabled by default in a virtual network. To re-enable these features, you must enable managed identity for storage accounts you intend to use in the studio.
The following operations are disabled by default in a virtual network:
Preview data in the studio.
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/how-to-access-data
NEW QUESTION # 62
You are a lead data scientist for a project that tracks the health and migration of birds. You create a multi-image classification deep learning model that uses a set of labeled bird photos collected by experts. You plan to use the model to develop a cross-platform mobile app that predicts the species of bird captured by app users.
You must test and deploy the trained model as a web service. The deployed model must meet the following requirements:
* An authenticated connection must not be required for testing.
* The deployed model must perform with low latency during inferencing.
* The REST endpoints must be scalable and should have a capacity to handle large number of requests when multiple end users are using the mobile application.
You need to verify that the web service returns predictions in the expected JSON format when a valid REST request is submitted.
Which compute resources should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation
Box 1: ds-workstation notebook VM
An authenticated connection must not be required for testing.
On a Microsoft Azure virtual machine (VM), including a Data Science Virtual Machine (DSVM), you create local user accounts while provisioning the VM. Users then authenticate to the VM by using these credentials.
Box 2: gpu-compute cluster
Image classification is well suited for GPU compute clusters
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/data-science-virtual-machine/dsvm-common-identity
https://docs.microsoft.com/en-us/azure/architecture/reference-architectures/ai/training-deep-learning
NEW QUESTION # 63
You create a multi-class image classification deep learning experiment by using the PyTorch framework. You plan to run the experiment on an Azure Compute cluster that has nodes with GPU's.
You need to define an Azure Machine Learning service pipeline to perform the monthly retraining of the image classification model. The pipeline must run with minimal cost and minimize the time required to train the model.
Which three pipeline steps should you run in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Answer:
Explanation:
Explanation
Step 1: Configure a DataTransferStep() to fetch new image data...
Step 2: Configure a PythonScriptStep() to run image_resize.y on the cpu-compute compute target.
Step 3: Configure the EstimatorStep() to run training script on the gpu_compute computer target.
The PyTorch estimator provides a simple way of launching a PyTorch training job on a compute target.
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/how-to-train-pytorch
NEW QUESTION # 64
You create an Azure Machine Learning workspace.
You must implement dedicated compute for model training in the workspace by using Azure Synapse compute resources. The solution must attach the dedicated compute and start an Azure Synapse session.
You need to implement the compute resources.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.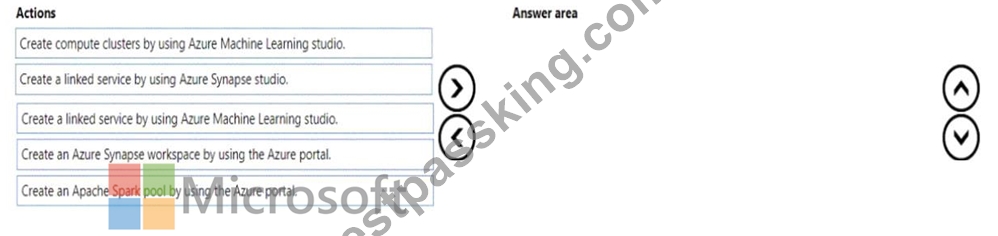
Answer:
Explanation:
Explanation
NEW QUESTION # 65
You have an Azure Machine Learning workspace named Workspace 1 Workspace! has a registered Mlflow model named model 1 with PyFunc flavor You plan to deploy model1 to an online endpoint named endpoint1 without egress connectivity by using Azure Machine learning Python SDK vl You have the following code: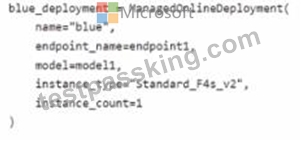
You need to add a parameter to the ManagedOnllneDeployment object to ensure the model deploys successfully Solution: Add the scoring_script parameter.
Does the solution meet the goal?
- A. No
- B. Yes
Answer: B
NEW QUESTION # 66
You create an Azure Machine learning workspace. The workspace contains a folder named src. The folder contains a Python script named script 1 .py.
You use the Azure Machine Learning Python SDK v2 to create a control script. You must use the control script to run script l.py as part of a training job.
You need to complete the section of script that defines the job parameters.
How should you complete the script? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation:
NEW QUESTION # 67
You need to define an evaluation strategy for the crowd sentiment models.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.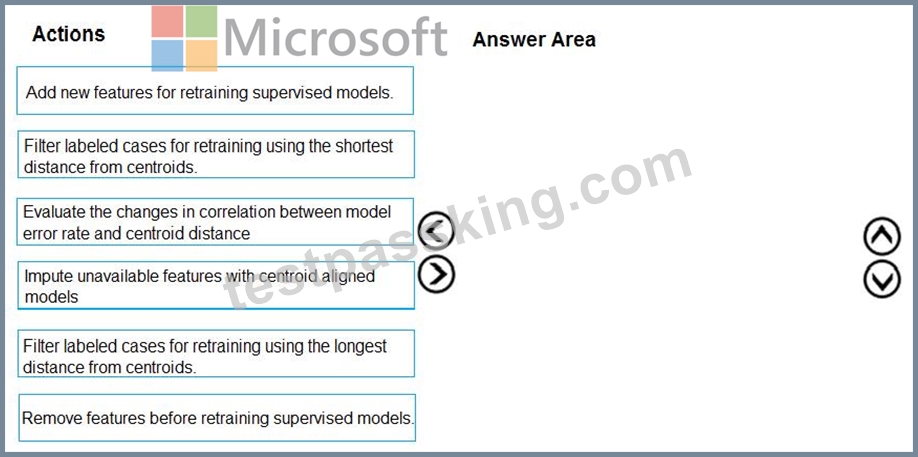
Answer:
Explanation:
1 - Add new features for retraining supervised models.
2 - Evaluate the changes in correlation between model error rate and centroid distance
3 - Filter labeled cases for retraining using the shortest distance from centroids.
Reference:
https://en.wikipedia.org/wiki/Nearest_centroid_classifier
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/sweep-clustering
NEW QUESTION # 68
You need to produce a visualization for the diagnostic test evaluation according to the data visualization requirements.
Which three modules should you recommend be used in sequence? To answer, move the appropriate modules from the list of modules to the answer area and arrange them in the correct order.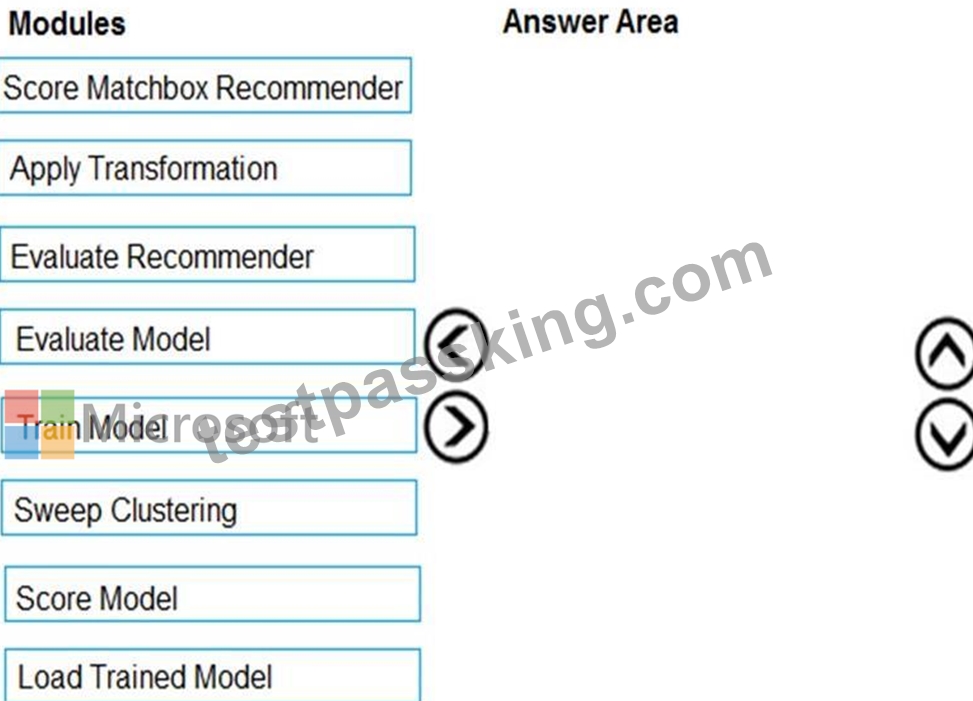
Answer:
Explanation:
Explanation
Step 1: Sweep Clustering
Start by using the "Tune Model Hyperparameters" module to select the best sets of parameters for each of the models we're considering.
One of the interesting things about the "Tune Model Hyperparameters" module is that it not only outputs the results from the Tuning, it also outputs the Trained Model.
Step 2: Train Model
Step 3: Evaluate Model
Scenario: You need to provide the test results to the Fabrikam Residences team. You create data visualizations to aid in presenting the results.
You must produce a Receiver Operating Characteristic (ROC) curve to conduct a diagnostic test evaluation of the model. You need to select appropriate methods for producing the ROC curve in Azure Machine Learning Studio to compare the Two-Class Decision Forest and the Two-Class Decision Jungle modules with one another.
References:
http://breaking-bi.blogspot.com/2017/01/azure-machine-learning-model-evaluation.html
NEW QUESTION # 69
You are using Azure Machine Learning to train machine learning models. You need a compute target on which to remotely run the training script. You run the following Python code:

Answer:
Explanation:
Reference:
https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.core.compute.amlcompute.amlcomputeprovisioningconfiguration
https://docs.microsoft.com/en-us/azure/machine-learning/how-to-create-attach-compute-studio
NEW QUESTION # 70
You manage an Azure Machine Learning workspace named workspace1 by using the Python SDK v2.
The default datastore of workspace1 contains a folder named sample_data. The folder structure contains the following content:
You write Python SDK v2 code to materialize the data from the files in the sample.data folder into a Pandas data frame. You need to complete the Python SDK v2 code to use the MLTaWe folder as the materialization blueprint. How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation:
NEW QUESTION # 71 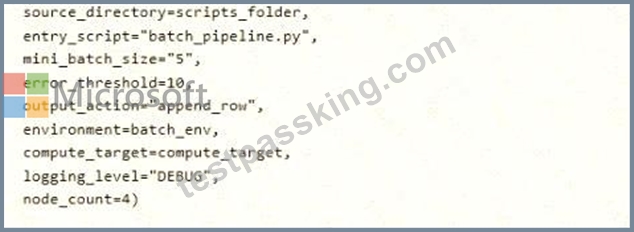
You need to obtain the output from the pipeline execution. Where will you find the output?
- A. a file named parallel_run_step.txt located in the output folder
- B. the Inference Clusters tab in Machine Learning studio
- C. the debug log
- D. the Activity Log in the Azure portal for the Machine Learning workspace
- E. the digitjdentification.py script
Answer: A
Explanation:
output_action (str): How the output is to be organized. Currently supported values are 'append_row' and
'summary_only'.
'append_row' - All values output by run() method invocations will be aggregated into one unique file named parallel_run_step.txt that is created in the output location.
'summary_only'
Reference:
https://docs.microsoft.com/en-us/python/api/azureml-contrib-pipeline-steps/azureml.contrib.pipeline.steps.
parallelrunconfig
NEW QUESTION # 72
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Python script named train.py in a local folder named scripts. The script trains a regression model by using scikit-learn. The script includes code to load a training data file which is also located in the scripts folder.
You must run the script as an Azure ML experiment on a compute cluster named aml-compute.
You need to configure the run to ensure that the environment includes the required packages for model training. You have instantiated a variable named aml-compute that references the target compute cluster.
Solution: Run the following code:
Does the solution meet the goal?
- A. Yes
- B. No
Answer: B
Explanation:
The scikit-learn estimator provides a simple way of launching a scikit-learn training job on a compute target. It is implemented through the SKLearn class, which can be used to support single-node CPU training.
Example:
from azureml.train.sklearn import SKLearn
}
estimator = SKLearn(source_directory=project_folder,
compute_target=compute_target,
entry_script='train_iris.py'
)
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/how-to-train-scikit-learn
NEW QUESTION # 73
You are performing clustering by using the K-means algorithm.
You need to define the possible termination conditions.
Which three conditions can you use? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
- A. Centroids do not change between iterations.
- B. The residual sum of squares (RSS) rises above a threshold.
- C. The sum of distances between centroids reaches a maximum.
- D. A fixed number of iterations is executed.
- E. The residual sum of squares (RSS) falls below a threshold.
Answer: A,D,E
Explanation:
References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/k-means-clustering
https://nlp.stanford.edu/IR-book/html/htmledition/k-means-1.html
NEW QUESTION # 74
You configure a Deep Learning Virtual Machine for Windows.
You need to recommend tools and frameworks to perform the following:
Build deep rwur.il network (DNN) models.
Perform interactive data exploration and visualization.
Which tools and frameworks should you recommend? To answer, drag the appropriate tools to the correct tasks. Each tool may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.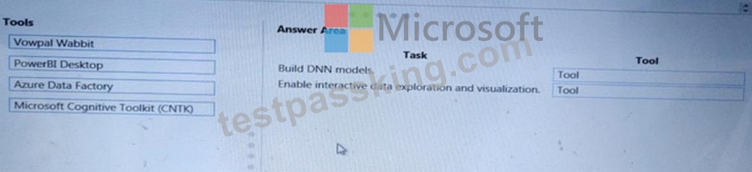
Answer:
Explanation:
NEW QUESTION # 75
You manage an Azure At Foundry project. You deploy an Azure OpenAI Service chat model. You configure the development environment with the necessary packages to build a Prompt flow in Visual Studio Code IDE.
You create a Python file called chat.py. You must configure the large language model with 0.2 as the temperature.
You need to develop the chat application.
Which two actions should you perform? Each correct answer presents part of the solution. Choose two.
NOTE: Each correct selection is worth one point.
- A. Configure the prompt template to reference the deployed Azure OpenAI chat model.
- B. Configure the project client to reference the deployed Azure OpenAI chat model.
- C. Use the render0 function to reference the deployed Azure OpenAI chat model.
- D. Use chat.complete0 to configure the temperature of the deployed model.
- E. Configure the temperature in the prompt template.
Answer: B,D
NEW QUESTION # 76
You have several machine learning models registered in an Azure Machine Learning workspace.
You must use the Fairlearn dashboard to assess fairness in a selected model.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.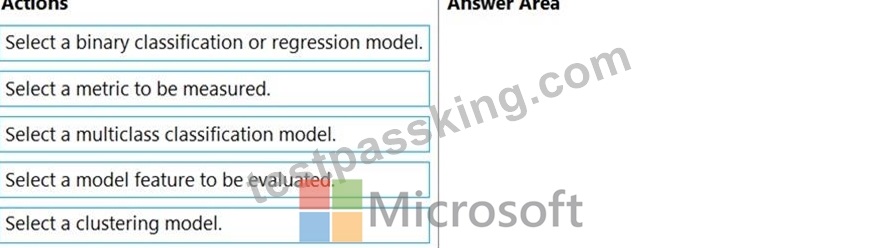
Answer:
Explanation: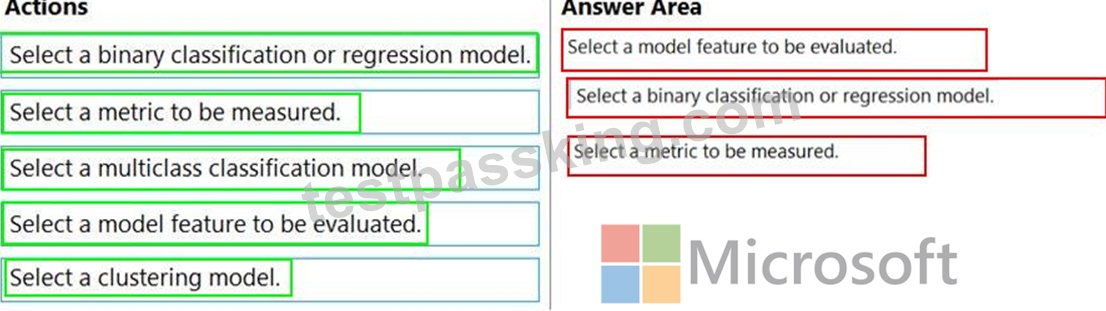
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/how-to-machine-learning-fairness-aml
NEW QUESTION # 77
You are developing code to analyse a dataset that includes age information for a large group of diabetes patients. You create an Azure Machine Learning workspace and install all required libraries. You set the privacy budget to 1.0).
You must analyze the dataset and preserve data privacy. The code must run twice before the privacy budget is depleted.
You need to complete the code.
Which values should you use? To answer, select the appropriate options m the answer area.
NOTE: Each correct selection is worth one point.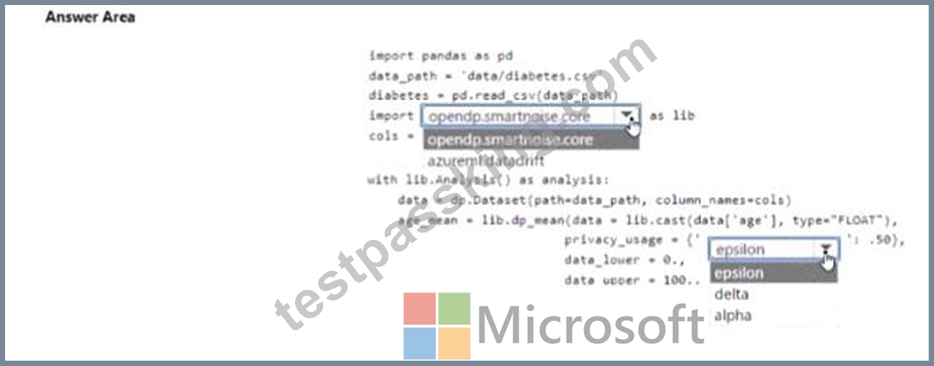
Answer:
Explanation: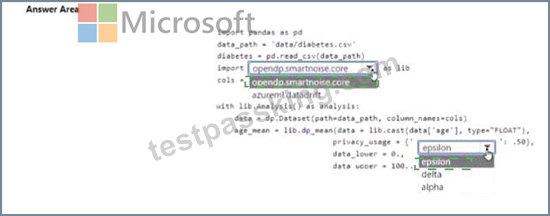
Explanation
NEW QUESTION # 78
You are authoring a notebook in Azure Machine Learning studio.
You must install packages from the notebook into the currently running kernel. The installation must be limited to the currently running kernel only.
You need to install the packages.
Which magic function should you use?
- A. !pip
- B. %load
- C. %pip
- D. !conda
Answer: C
Explanation:
The !pip command installs packages from the notebook into the currently running kernel but does not limit the installation to the currently running kernel only.
This means that if you have multiple kernels running in your notebook, !pip will install the package in all of them.
NEW QUESTION # 79
You plan to provision an Azure Machine Learning Basic edition workspace for a data science project.
You need to identify the tasks you will be able to perform in the workspace.
Which three tasks will you be able to perform? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
- A. Create a tabular dataset that supports versioning.
- B. Create an Azure Kubernetes Service (AKS) inference cluster.
- C. Use the designer to train a model by dragging and dropping pre-defined modules.
- D. Use the Automated Machine Learning user interface to train a model.
- E. Create a Compute Instance and use it to run code in Jupyter notebooks.
Answer: A,B,E
Explanation:
Reference:
https://azure.microsoft.com/en-us/pricing/details/machine-learning/
Topic 2, Case Study 2
Case study
Overview
You are a data scientist for Fabrikam Residences, a company specializing in quality private and commercial property in the United States. Fabrikam Residences is considering expanding into Europe and has asked you to investigate prices for private residences in major European cities. You use Azure Machine Learning Studio to measure the median value of properties. You produce a regression model to predict property prices by using the Linear Regression and Bayesian Linear Regression modules.
Datasets
There are two datasets in CSV format that contain property details for two cities, London and Paris, with the following columns: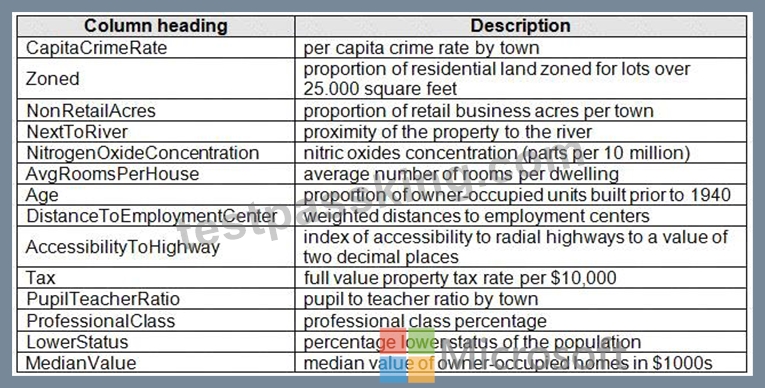
The two datasets have been added to Azure Machine Learning Studio as separate datasets and included as the starting point of the experiment.
Dataset issues
The AccessibilityToHighway column in both datasets contains missing values. The missing data must be replaced with new data so that it is modeled conditionally using the other variables in the data before filling in the missing values.
Columns in each dataset contain missing and null values. The dataset also contains many outliers. The Age column has a high proportion of outliers. You need to remove the rows that have outliers in the Age column.
The MedianValue and AvgRoomsinHouse columns both hold data in numeric format. You need to select a feature selection algorithm to analyze the relationship between the two columns in more detail.
Model fit
The model shows signs of overfitting. You need to produce a more refined regression model that reduces the overfitting.
Experiment requirements
You must set up the experiment to cross-validate the Linear Regression and Bayesian Linear Regression modules to evaluate performance.
In each case, the predictor of the dataset is the column named MedianValue. An initial investigation showed that the datasets are identical in structure apart from the MedianValue column. The smaller Paris dataset contains the MedianValue in text format, whereas the larger London dataset contains the MedianValue in numerical format. You must ensure that the datatype of the MedianValue column of the Paris dataset matches the structure of the London dataset.
You must prioritize the columns of data for predicting the outcome. You must use non-parameters statistics to measure the relationships.
You must use a feature selection algorithm to analyze the relationship between the MedianValue and AvgRoomsinHouse columns.
Model training
Given a trained model and a test dataset, you need to compute the permutation feature importance scores of feature variables. You need to set up the Permutation Feature Importance module to select the correct metric to investigate the model's accuracy and replicate the findings.
You want to configure hyperparameters in the model learning process to speed the learning phase by using hyperparameters. In addition, this configuration should cancel the lowest performing runs at each evaluation interval, thereby directing effort and resources towards models that are more likely to be successful.
You are concerned that the model might not efficiently use compute resources in hyperparameter tuning. You also are concerned that the model might prevent an increase in the overall tuning time. Therefore, you need to implement an early stopping criterion on models that provides savings without terminating promising jobs.
Testing
You must produce multiple partitions of a dataset based on sampling using the Partition and Sample module in Azure Machine Learning Studio. You must create three equal partitions for cross-validation. You must also configure the cross-validation process so that the rows in the test and training datasets are divided evenly by properties that are near each city's main river. The data that identifies that a property is near a river is held in the column named NextToRiver. You want to complete this task before the data goes through the sampling process.
When you train a Linear Regression module using a property dataset that shows data for property prices for a large city, you need to determine the best features to use in a model. You can choose standard metrics provided to measure performance before and after the feature importance process completes. You must ensure that the distribution of the features across multiple training models is consistent.
Data visualization
You need to provide the test results to the Fabrikam Residences team. You create data visualizations to aid in presenting the results.
You must produce a Receiver Operating Characteristic (ROC) curve to conduct a diagnostic test evaluation of the model. You need to select appropriate methods for producing the ROC curve in Azure Machine Learning Studio to compare the Two-Class Decision Forest and the Two-Class Decision Jungle modules with one another.
NEW QUESTION # 80
You are analyzing the asymmetry in a statistical distribution.
The following image contains two density curves that show the probability distribution of two datasets.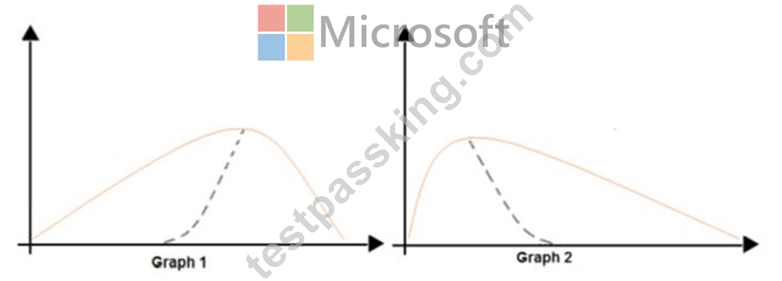
Use the drop-down menus to select the answer choice that answers each question based on the information presented in the graphic.
NOTE: Each correct selection is worth one point.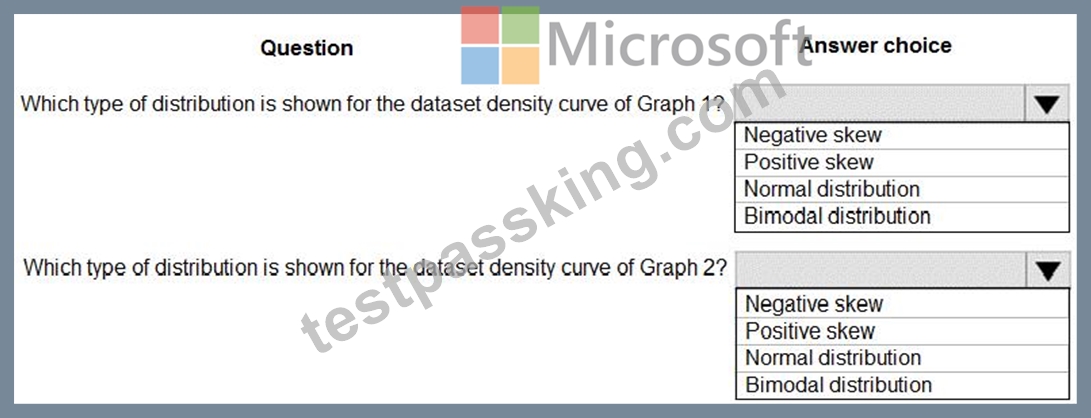
Answer:
Explanation: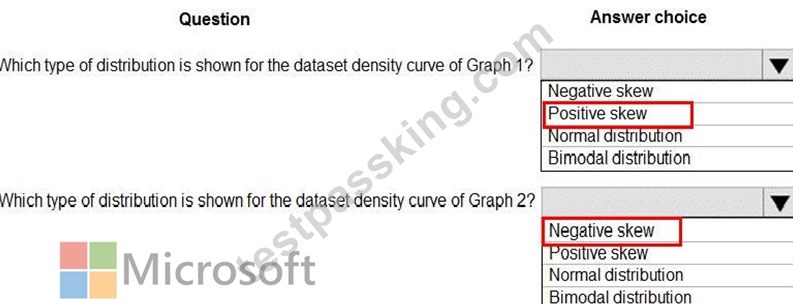
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/compute-elementary-statistics
NEW QUESTION # 81
You have the following Azure subscriptions and Azure Machine Learning service workspaces:
You need to obtain a reference to the ml-project workspace.
Solution: Run the following Python code:
Does the solution meet the goal?
- A. Yes
- B. No
Answer: B
NEW QUESTION # 82
Drag and Drop Question
You need to implement source control for scripts in an Azure Machine Learning workspace. You use a terminal window in the Azure Machine Learning Notebook tab.
You must authenticate your Git account with SSH.
You need to generate a new SSH key.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Answer:
Explanation:
NEW QUESTION # 83
You are developing code to analyse a dataset that includes age information for a large group of diabetes patients. You create an Azure Machine Learning workspace and install all required libraries. You set the privacy budget to 1.0).
You must analyze the dataset and preserve data privacy. The code must run twice before the privacy budget is depleted.
You need to complete the code.
Which values should you use? To answer, select the appropriate options m the answer area.
NOTE: Each correct selection is worth one point.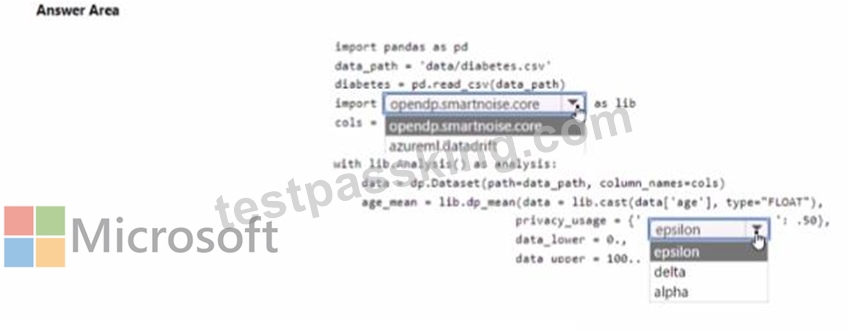
Answer:
Explanation: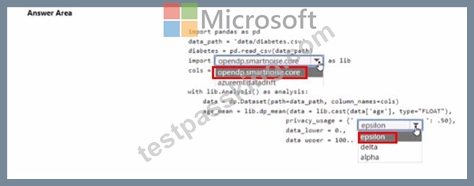
NEW QUESTION # 84
You create a multi-class image classification deep learning model.
The model must be retrained monthly with the new image data fetched from a public web portal. You create an Azure Machine Learning pipeline to fetch new data, standardize the size of images, and retrain the model.
You need to use the Azure Machine Learning SDK to configure the schedule for the pipeline.
Which four actions should you perform in sequence. To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.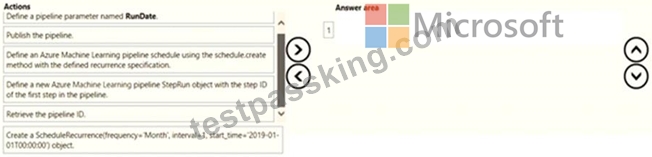
Answer:
Explanation: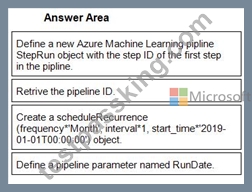
1 - Define a new Azure Machine Learning pipline StepRun object with the step ID of the first step in the pipline.
2 - Retrive the pipeline ID.
3 - Create a scheduleRecurrence(frequency*'Month', interval*1, start_time*'2019-01-01T00:00:00') object.
4 - Define a pipeline parameter named RunDate.
NEW QUESTION # 85
You are using the Azure Machine Learning designer to transform a dataset by using an Execute Python Script component and custom code.
You need to define the method signature for the Execute Python Script component and return value type.
What should you define? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation
NEW QUESTION # 86
......
DP-100 Dumps for Pass Guaranteed - Pass DP-100 Exam: https://www.testpassking.com/DP-100-exam-testking-pass.html
DP-100 Exam Dumps - Try Best DP-100 Exam Questions: https://drive.google.com/open?id=1mkMxueQJq6xvCa75NVEtaHHPchgMLwmU